
HLD of a notification System: @iStream
/ 14 min read
Table of Contents
for the past few months i’ve been making my own Adaptive-bitrate-streaming platform like Twitch called iStream to learn about systems and stuff + eventually/hopefully -> land an internship;
This blog is more of an architectural discussion rather than a tutorial, and expects u to know the basics of system-design. Handling notifications according to me is one of the core concerns of any platform/business, for which we talk, about what i did and what could have been better; Validation of the discussions below are based on the blog’s publish date, which also acts as a reference marker.
init-NotifSystem :v0
moi started with a designing approach called as step-scaling which just means increase users gradually 1000-10k-1mill because it helps u focus step by step on the choke-points, sorta in a very linear manner, but discussions below are heavily-based on the current-active version;
-
even the smallest and the shittiest saas devs have different types of notifications which carry different weights in the backend logic, otp/payment/password-reset being the most important to an x-person made a post, taking a place of lesser importance, having different queues for each of them and pushing accordingly works for v0 ;
-
Polling is the bare minimal u do when u have 100-1000 users, it works till it doesn’t, u might also try push based updates or socket updates -> only to realize u want to store notifs for some time in the db cuz wat if the user reloads and u push through a socket-connection or a sse(server side events) the same time or wat if he wants to see older notifs, and wat not; u can use redis, but how much ram will u use for storing notifs.
-
redis is definitely good if there are multiple socket-servers and user is connected to lets say the 3rd one, and a notif originates from the 1st one, so u need memory access to know about the connected socket - done through redis-adapters
-
we have reached to a point where we have started to feel the need of a separate notification model so that a scheduler can pick failures for retries, and user getting a notif document in the db is a step towards guaranteed delivery.
notifSchema
- my current notif schema looks like -
const notifSchema = new Schema<INotification>({ userId: { type: Schema.Types.ObjectId, required: true, index: true }, actorId: { type: Schema.Types.ObjectId, required: true }, type: { type: String, required: true, enum: ["follow", "stream", "chat", "like"], }, }, { timestamps: { createdAt: true, updatedAt: false }, },);
// ( auto-delete after 7 days)notifSchema.index( { createdAt: 1 }, { expireAfterSeconds: 7 * 24 * 60 * 60 },);ps- having an index on userId helps mongoDB for easy lookup, not parsing and checking the value of each key, but uknow that already!
-
the problem i was facing here was - redelivery of failures (like how to identify, whom i have sent notifs and for whom to retry); i knew we have dedupe keys for this very fact, but storing dedupe in the db felt like a dumb decision; and i was pretty sure that majority of the retries would have had happened under 24hours of the notification being created; so wat i did was, i created a dedupe key in redis rather than db with a ttl of 1 day; its not a prod choice cuz here redis is being the single source of truth, which makes it a dumb design by backend fundamentals; iStream’s design still uses redis for dedupe;
-
the only thing i would like to pass to the future me is a line i remember from some system-design video: always keep more features/fields in the schema than u think; badges, pfp, etc, keep it generic enough to hold more than u think is required and try to keep things server side - keep the client as dumb as an ape - even OnClick->actions/links should be sent by the backend; as backend deployment is far more easier than an app-release;
-
we got ourself a pretty-basic design which can easily handle a little load in the initial phases of ur shitty saas; but inorder to scale even further we move to v2.
architecture diagram :v0
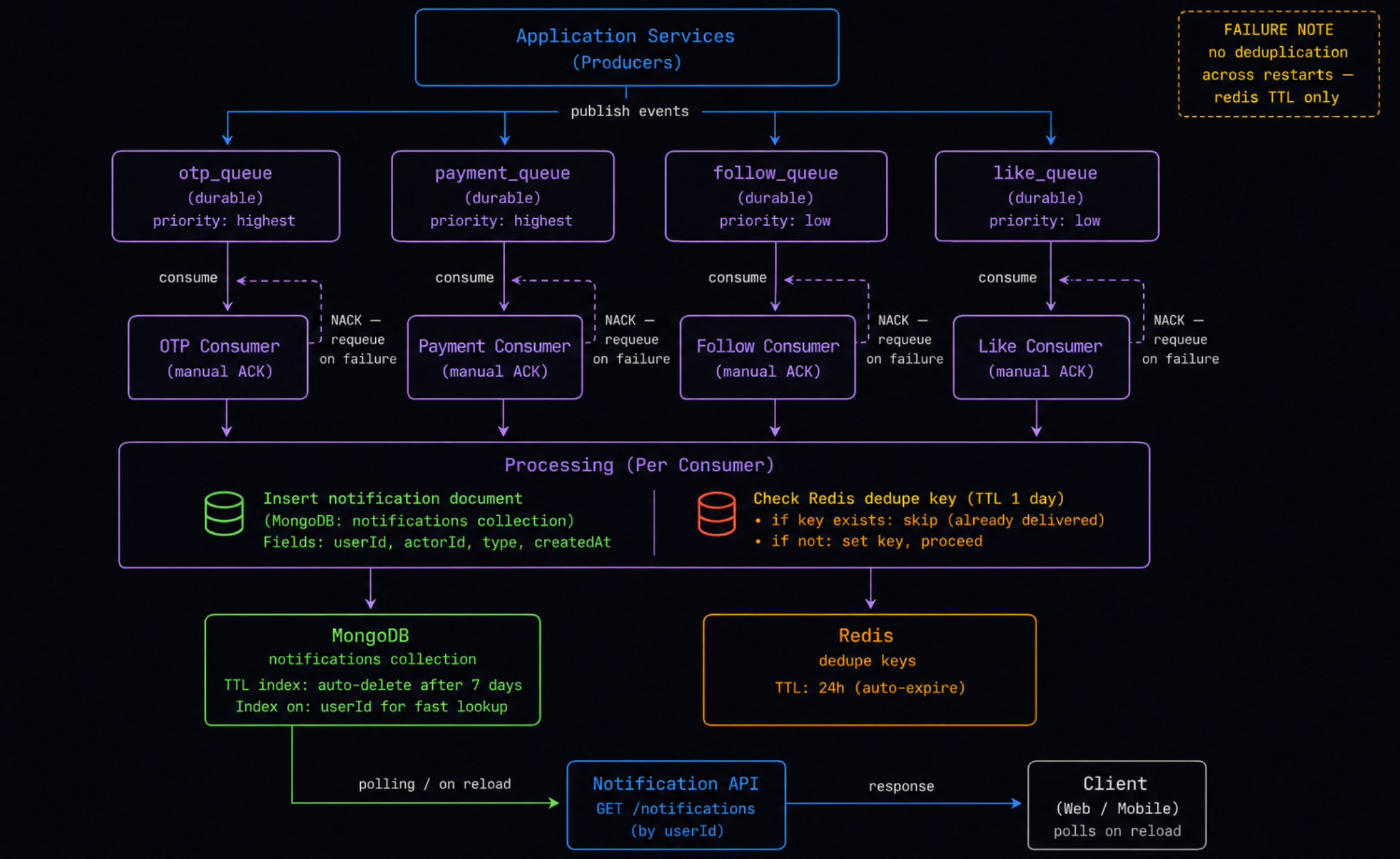
NotifSystem: v2
The whole working of the notification-service comes with a lot of DB load(especially reads), collecting various information from various services/db(user/payment/aggregator/etc), adding read replicas may do the work but may not be the most optimal answer; One thing u might suggest is adding more workers, but database has a limit for handling concurrent connections, Databases are not elastic, so u again hit a choke point :
rabbitMQ approach >
- The point of scaling is prioritizing - we have already discussed about each notif carrying different weight above, we discussed the naive fix of adding queues for different notifs but that also meant creating a new queue every time ur app wants a new notification type, leading to a dirty codebase -> RabbitMQ exchanges short-circuit this entirely. I used “exchangers” in iStream, here u categorize different msgs based on a routing key to land on a specific queue, with different prefetch type(); Ship a new notification type, add a routing key, done. The exchange figures out where it lands, and event automatically gets requeued on failure and inside dlq if fails multiple times;
kafka/kinesis approach >
-
this is a kafka specific case - or applies to any pull based queue
In kafka we have partitions, which keeps listening to do a fanout/send the notif, but there is a flaw here -
using kafka say, i publish a post_event to a topic -> if u have barely used kafka like me, the topic stores the data by default for 7 days as backlog if not consumed, ofc u can increase the period, and the no of partitions in a topic is the max no of consumers that will do the work in parallel - if u have less consumer than the partition, the leftover partition piles up the log - thats kafka for u;
“The use of Kafka naturally leads us to the celebrity problem - due to bad engineering, that we need to address (and partly because I want to put a photo of Sydney Sweeney).” 😭
the “celebrity problem” and prioritization

the kafka consumer can choke on the msg if the post is of a person with a lot of followers like Sydney Sweeney cuz That one message holds the partition hostage. Every message behind it waits -> so the learning was u never want a very long running process the part of kafka’s consumers, instead of the Kafka consumer doing the fan-out directly, it publishes individual notification tasks into SQS. Now you have hundreds of lightweight SQS workers consuming in parallel, each responsible for a single user notification. The fan-out is no longer a single long-running process but u can put a sqs in bw which can have 100’s of listeners and do the fanout job to the respective user;
Kafka: 1 event ("Sydney Sweeney posted") ↓
SQS dispatcher queue: 1 message → "start fan-out"
↓
Dispatcher worker: fetches 500 followers,publishes 500 tiny messages,requeues itself for next 500
↓ (repeats until all 20M followers paginated)
SQS delivery queue: 20 millionindividual "notify this one user" messages ↓
100s of delivery workers: each picks upONE message, does ONE insert + ONE publish to socket-servicefor the prioritization part- the workers pulling from sqs are context aware - if that worker fails mid-execution, it just log and republishes the message back to Kafka with an incremented retry header, preserving the event in the durable log rather than losing it, and pushes to dlq on multiple failed attempts;
so this becomes a more scalable architecture;
architecture diagram :v1
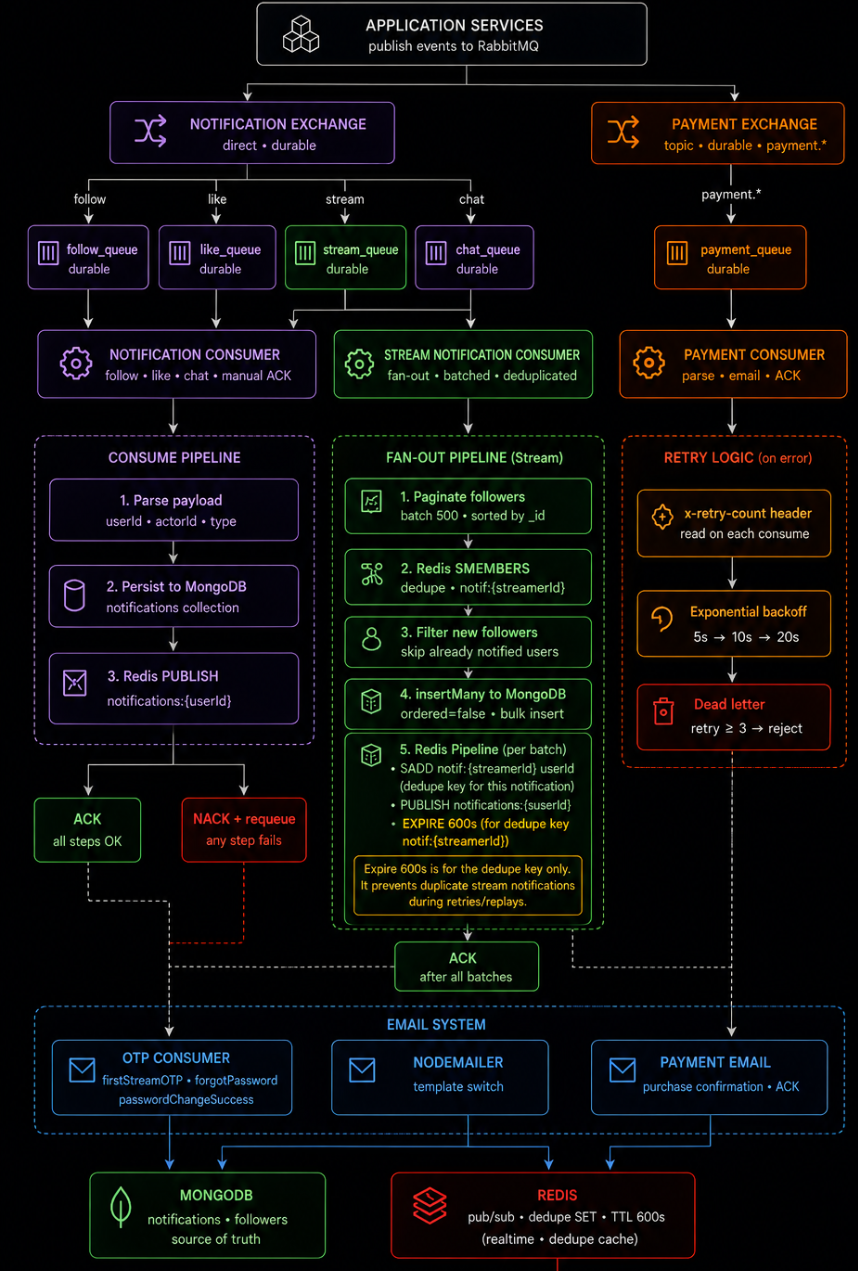
textual bs.
skip this if u understood the diag.
iStream’s notification system is built on a single RabbitMQ broker with two exchanges handling distinct traffic shapes. A direct exchange routes social events- follows, likes, chat, stream-start, by routing key into dedicated durable queues, each consumed independently with manual acknowledgment so a crash never silently drops a notification.
The stream-start path is the interesting one: rather than blasting every follower synchronously, the consumer paginates followers in batches of 500, checks a Redis SET for already-notified users (deduped by notif:{streamerId}, TTL 600s), bulk-inserts only the new ones via insertMany with ordered: false, and only then publishes the realtime update - so retries and replays during a stream-start never double-notify a follower. A separate topic exchange handles payment.*(topic-> only to streamline and evolve easily).
Failure handling is explicit: every consumer reads an x-retry-count header and applies exponential backoff (5s → 10s → 20s) before giving up and routing to a dead-letter path(to be added) after three attempts. Persistence and realtime delivery are deliberately split across two stores playing to their strengths: DB is the source of truth holding the notification documents and follower graph, while redis handles everything ephemeral - pub/sub for instant delivery to the socket layer, and the dedupe SET that exists purely to survive retries without becoming a second source of truth. It can be presented as a textbook architecture: durable by default, deduplicated where it actually matters, and cleanly separated by event weight.
issues in v1 + problems identified :
There are issues with my current implementation(v1) - though i tried to identify major bottlenecks and choke-points;
-
SPOF - The implementation is having a single Point of Failure. This is better understood with an example - in notification-service of iStream : lets say I have to announce a 50% discount mail to all the users - the intended queue will be under too much load and because all the queues are a part of the same process, even the payment-queue slows down;
This is a textbook case of head-of-line blocking, a high volume low-priority event (discount announcement) saturating the shared worker pool and starving high priority queues (payment, OTP) of processing capacity. The queues are logically separate but physically share the same process, the same worker threads, and the same broker connection pool. One noisy queue becomes everyone’s problem.
This is the noisy neighbor problem at the queue level, and it’s the exact reason v1’s flat queue architecture doesn’t survive real production load. A single marketing blast should never be able to delay a payment confirmation.
but the flat-process design isn’t the only SPOF here, the infra underneath it has the same problem at every layer:
-
RabbitMQ is a single broker - no clustering, no mirrored queues. it goes down, every queue stops at once. durable queues + persistent messages save you from message loss on restart, but there’s zero failover while it’s down.
-
MongoDB is a single node - no replica set. the notification documents are supposed to be the durability guarantee for the whole system, “guaranteed delivery” is the whole point of having a notif model in the first place, but a single mongo crash takes that guarantee down with it.
-
redis as a silent source of truth - already flagged this in v0, it’s still true in v1. the dedupe SET has no backing store. redis restarts mid-fanout, every in-flight dedupe key is gone, and the next retry redelivers notifications that were already sent. fine for a “like”, not fine for anything payment-adjacent.
none of these are exotic failures, they’re the boring kind that actually happen, single instance of anything is a SPOF until proven otherwise, and v1 has three of them stacked on top of each other.
-
-
Scaling Issues - Because this currently handles a lot of things at once, db writes/reads + sending mails + caching , its not highly scalable
(below text serves as a solution to the above listed problems) a cleaner seperation of concerns with increased code complexity/maintenance would prove to be more stable and easily scalable
-
notification-service/ → consumes: follow_queue, like_queue, chat_queue → light, stateless, scale freely → prefetch: 10
-
stream-fanout-service/ → consumes: stream_queue only → heavy, long-running batches → prefetch: 1, scale carefully
-
mail-service/ → consumes: otp_queue → I/O bound on SMTP, scale independently
-
payment-service/ → consumes: payment_queue → never share a process with anything else → prefetch: 1, dead letter queue mandatory
-
when i would use k8(or even my own autoscaler) i would be able to add replicas for a particular service if its under load; replicas of the services don’t help if RabbitMQ or Mongo themselves are still single-node, that part needs clustering;
-
When processing Notifications, if overloaded, will need a timeout due to machine limitations and users would have to wait for the msgs;
-
no dlq/dlx + no observability-> i plan to add them in this project to add some mechanism of retrieval and retry for the failed ones + easier metric logging thru prometheus or grafana (resume-decoration tbh)
-
Dedupe key in iStream is set only for a fanout-job to all the followers about the stream_start notification - should have had extended it to all the notifs and even mails for no duplicates;
-
SMTP service(node-mailer) is a single point of failure too, mail-service → SMTP provider goes down → OTP queue backs up → users can’t login → everything breaks. No fallback provider, no retry with exponential backoff mentioned.
-
No backpressure or queuing visibility under load - if the notification service gets overloaded, there’s currently no circuit breaker or timeout mechanism; messages just pile up in the queue with no signal to the user that their notification is delayed versus lost. A proper implementation needs either a timeout-and-fail-fast policy or a status indicator so “pending” feels like pending;
pattern-subscribe on the backend;
a case worth mentioning -
so the /notify namespace had a classic distributed socket problem - a notif originating on server A had no way of reaching a user connected to server B; ape’s first instinct was a redis channel per user, subscribe individually, sounds clean right? i held with this approach for a month but soon realized - too many subscriptions to manage, and remove as users connect/disconnect, doesn’t scale past a few hundred concurrent users; another option was - a single global channel felt like the opposite extreme - every server processing every notification for every user, noisy and wasteful; the fix was PSUBSCRIBE notify:* - one pattern-subscriber per socket server listening to all notify:{userId} channels at once; when a message lands on notify:123 , the server checks locally if any connected socket belongs to that user - emits if yes, ignores if no; u trade N individual subscriptions for 1 pattern subscription + a cheap local filter check; redis’s connection bookkeeping stays sane, the filter cost is negligible - the only tradeoff is every server receives every notify event and discards the irrelevant ones locally, i cannot find any good solution for it, and the alternatives that come to mind are worse in every direction;
Prod services which caught my eye -
Instagram and Linkedin uses these heavily, to prevent users from getting spammed with messages;
notification decider
to decide if the user actually needs a notification
- The system checks user notification settings to determine if an alert should be sent immediately, bundled into a digest, or skipped entirely, its simply a rules engine - User has muted this person? Digest mode? DND hours?
- Not just the DND toggle, actual timezone resolution per user so a 2am notification in IST doesn’t fire at 2am for someone in a different timezone, this layer is not very common;
notification aggregator-
this is what is responsible for - ” Sydney Sweeny + 19 others liked your post”
- most of the time it also comes with a template engine abstraction which customizes ur notifications/mails acc to ur preferences before sending them to u
- the worker which picks up ur notifications and keeps aggregating the notification of the same type/object to prevent the feeling of spam. the choice of time quantum is the most important, how long do u want to aggregate ?
A rate-limiter : necessity
this also can be placed in the issue section of v1.
Before RabbitMQ (at the producer / API layer) - for preventing a single user or buggy service from flooding the exchange with garbage. After RabbitMQ, before delivery (at the consumer / worker layer) - for protecting the user the same logic holds true for kafka.
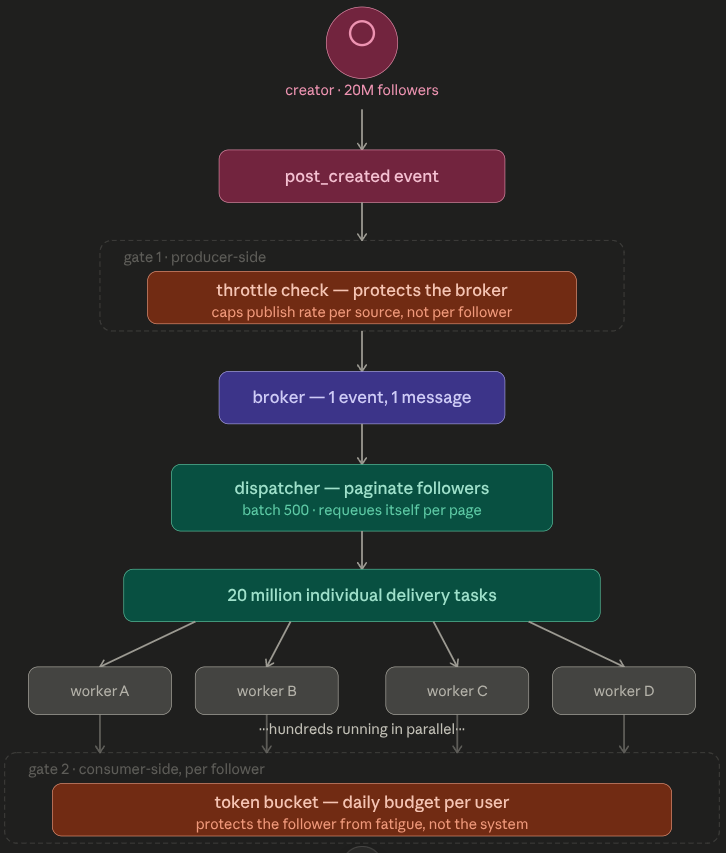
-
Per-user, per-channel caps so a buggy producer can’t blast someone with 500 push notifications in a minute/ or someone doesn’t misuse it(eg- in my case- a streamer starting and ending a new stream every few mins). Usually a sliding window counter in Redis-> notif:throttle:{userId}:{channel} or even a token bucket algo;
-
Instagram caps push notifications hard; this is why you don’t get a notification for every single like in real time during viral moments.